大模型自从2023年火遍全球之后,所有人都在做AI相关的研发,今天在即刻也看见了一篇动态:全世界的男生都在做AI应用开发,全世界的女生都在做播客,有点身边统计学的意味,因为即刻确实是一个很小资,或者很爱这些看着非常前沿的社区。
说实话,很多时候我都不太想对外说我是做人工智能或者做大模型相关内容的从业者,因为我总感觉自己对AI也好,对深度学习也好,并没有什么了解,没有发过论文,没有写过算子,没搞过CV,没搞过树模型,更没搞过文生图之类的任务,我只了解NLP这么一个子领域里极小极小的一点点内容,这个黑盒子对我的能力来说,真的是太大了一点。
说回AI相关的研发,从2023年的年初,大家都在说,OpenAI给出了大模型研发的新范式,Pretrain-SFT-RLHF,然而,从2023年到2025年初,我有所涉及的其实只有SFT,Pretrian的工作其实都非常少,找不到数据,找不到优质的,能提升任务性能的后训练数据,以及,基座模型真的太强了,已经能做的非常非常好了,要继续深究,继续在基础能力上进行提升,其实需要对业务有非常深刻的理解。以及跟随任务的演进,引入更多的优质数据。因此,鉴于这类困境,我们能做的事情基本上就集中在SFT这个子任务了。说是子任务也不太对,监督学习历来是深度学习的重中之重,我想现今绝大多数的人工智能模型,其智能的激发大多来自这个阶段,而且业务上的能力也大多来自这个阶段,只要有足够好的任务数据,微调数据,啥样的基座都能给出一个不错的效果,而预训练或者RLHF之类的优化,反而是锦上添花的工作。
但是,我们不能总着眼于那些唾手可得的低垂的果实,作为相关业务从业者,我们至少也要往前看到那些需要稍微跳一下才能解决的任务。因此,我们还是要进入强化学习的领域来进一步优化咱们的业务模型不是吗。
强化模型说实话之前我们接触的很少,我对此为数不多的认知就是摇臂赌博机,还有openai开源的那些强化学习小游戏,简而言之,我认为强化学习是一个更加端到端的任务,我们希望能从更高维度的任务指标,来指导模型的参数优化,因此将这个过程抽象成模型和环境的交互(Agent与Env的交互也可以)
在交互的过程中,模型和环境会分别产生动作(action)状态(state)以及(reward),我们总是根据某些时间点下的状态,来优化我们的模型参数,以进一步提升性能。
上面是一个更加贴合真实师姐的强化学习的例子,而在语言模型中,强化学习会稍微抽象一些。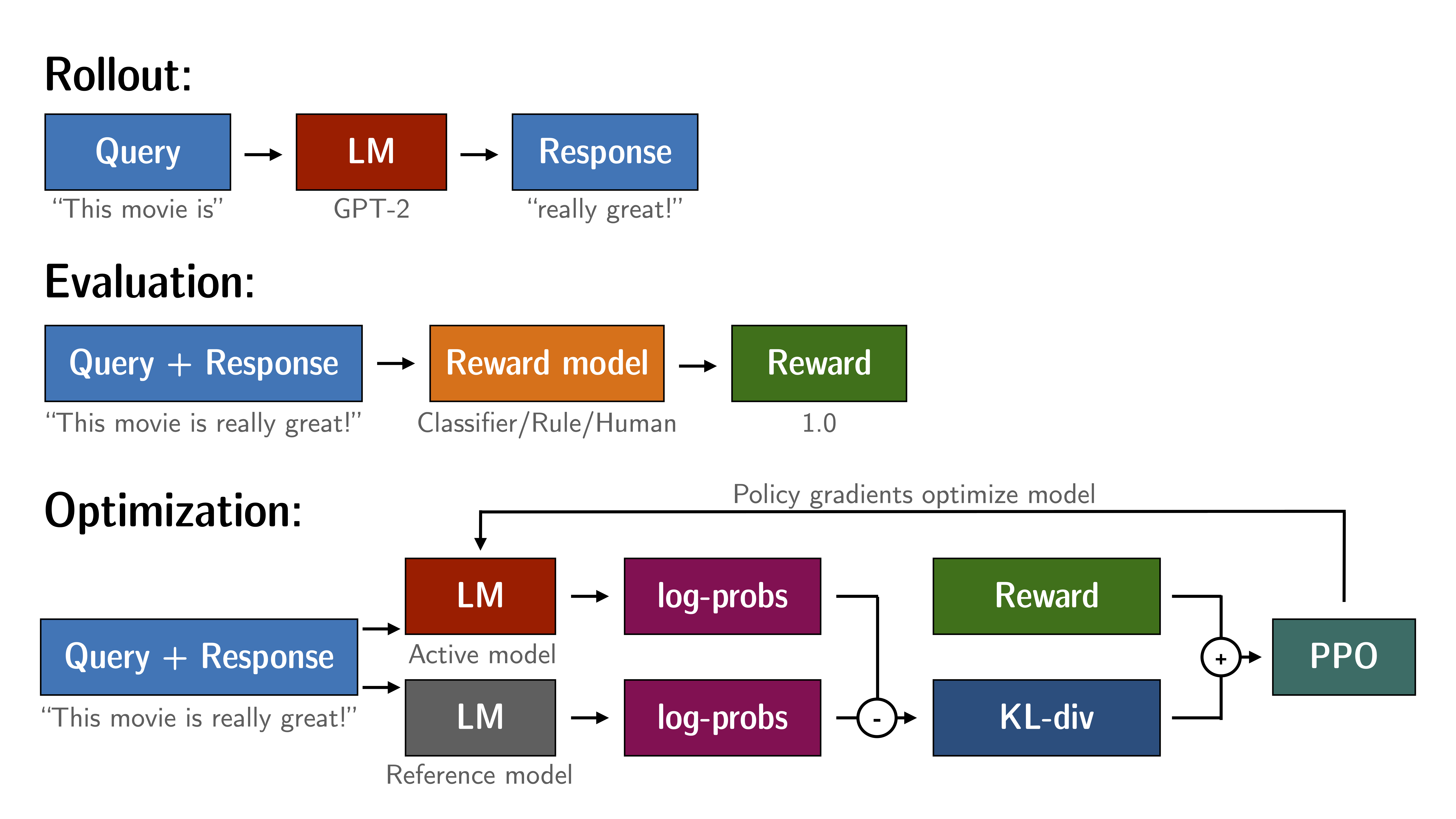
如图所示,在大多数的强化学习中,都会有至少两个模型被加载,一个用于训练,一个用于参考,而上文所说的更高维度的端到端的标签,便是这图中evaluation里的reward值,通过分类器、人类或者规则给出的价值,模型在一次次action中,寻找提高reward的路径。
然而,这里便有许多困难需要处理
reward使用模型还是规则?
使用模型的话,奖励模型该怎么训练,该怎么确认一个奖励模型足够好?
使用规则的话,如何判断语义类的任务,比如评判输出的一句话够不够好?
如何防止模型的reward hacking?
如何设置reward数值?reward正数负数是否会影响最终的性能?
